In recent years, large language models (LLMs) have gained widespread popularity for their ability to process, generate, and manipulate texts in various languages. While these models have shown impressive capabilities in producing human-like text, they are also prone to what researchers refer to as hallucinations. These hallucinations occur when an LLM generates responses that are nonsensical, inaccurate, or inappropriate.
Researchers at DeepMind have developed a novel procedure to address the issue of hallucinations in LLMs. Their approach involves using the LLM itself to evaluate the similarity between its potential responses for a given query. By leveraging conformal prediction techniques, the researchers have devised an abstention procedure that helps the model identify instances where it should refrain from responding, such as by stating “I don’t know.”
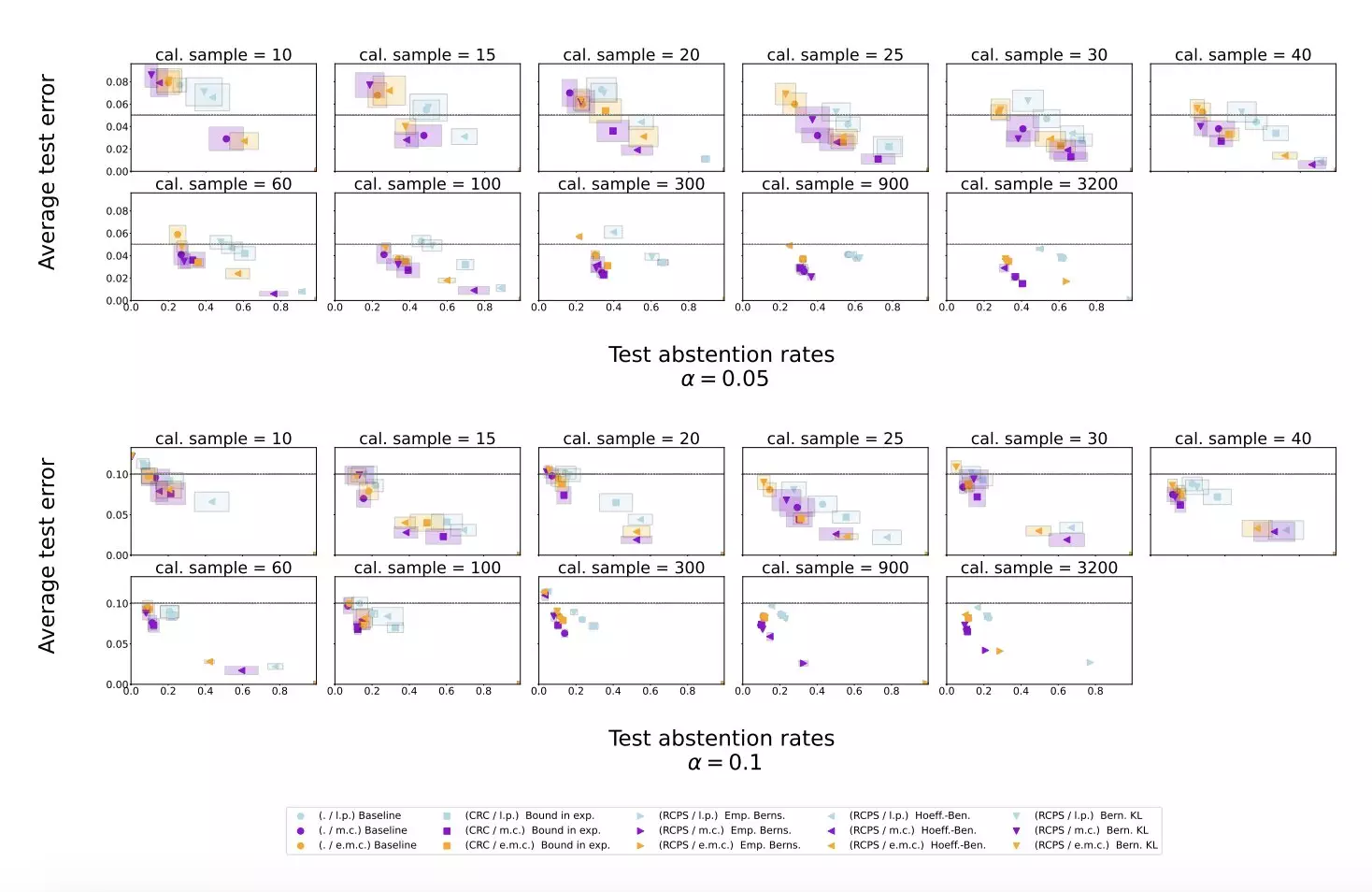
To test the effectiveness of their approach, Yadkori, Kuzborskij, and their team conducted experiments using two publicly available datasets: Temporal Sequences and TriviaQA. They applied their method to Gemini Pro, an LLM developed at Google, and found that it reliably reduced the hallucination rate while maintaining a reasonable abstention rate. The results of the experiments indicated that the proposed approach outperformed baseline scoring procedures in mitigating LLM hallucinations.
Implications for the Future of Language Models
The findings of this study by DeepMind suggest that self-evaluation techniques can significantly improve the reliability of LLMs and help prevent them from hallucinating. By enabling models to abstain from answering when their responses are likely to be nonsensical or untrustworthy, this approach could lead to significant advancements in the development of language models. It may also pave the way for the creation of similar procedures that could be adopted by professionals worldwide to enhance the performance of LLMs.
The research conducted by Yadkori, Kuzborskij, and their colleagues highlights the importance of self-evaluation in improving the accuracy and reliability of large language models. By developing a method that allows LLMs to assess the quality of their responses, researchers have taken a significant step towards mitigating the issue of hallucinations in these models. The success of this approach not only contributes to the advancement of LLM technology but also opens up new possibilities for enhancing the performance of language models in various applications.
Leave a Reply