The capability of Large Language Models (LLMs) like the GPT-4 model to comprehend written prompts and craft appropriate responses in multiple languages has been nothing short of astonishing for users on platforms such as ChatGPT. The question on many minds is whether the texts and answers generated by these models are so lifelike that they could be mistaken for human-written content. Recently, researchers at UC San Diego embarked on a journey to explore this inquiry by conducting a Turing test. This test, named after computer scientist Alan Turing, aims to evaluate the degree to which a machine showcases human-like intelligence. The outcomes of their investigation, as delineated in a paper published on the arXiv server, indicate that individuals find it challenging to differentiate between the GPT-4 model and a human participant in a two-person conversation setting.
The inception of this study can be traced back to a class focusing on LLMs, where co-author Cameron Jones was intrigued by the idea of testing whether an LLM could pass the Turing test and the ramifications of such an achievement. The initial experiment, supervised by Professor Bergen, suggested that GPT-4 could successfully masquerade as human in about half of the interactions. However, due to inadequate control over certain variables that could impact the results, a second experiment was conducted to refine their findings. The subsequent study yielded more conclusive results, which were later detailed in their paper.
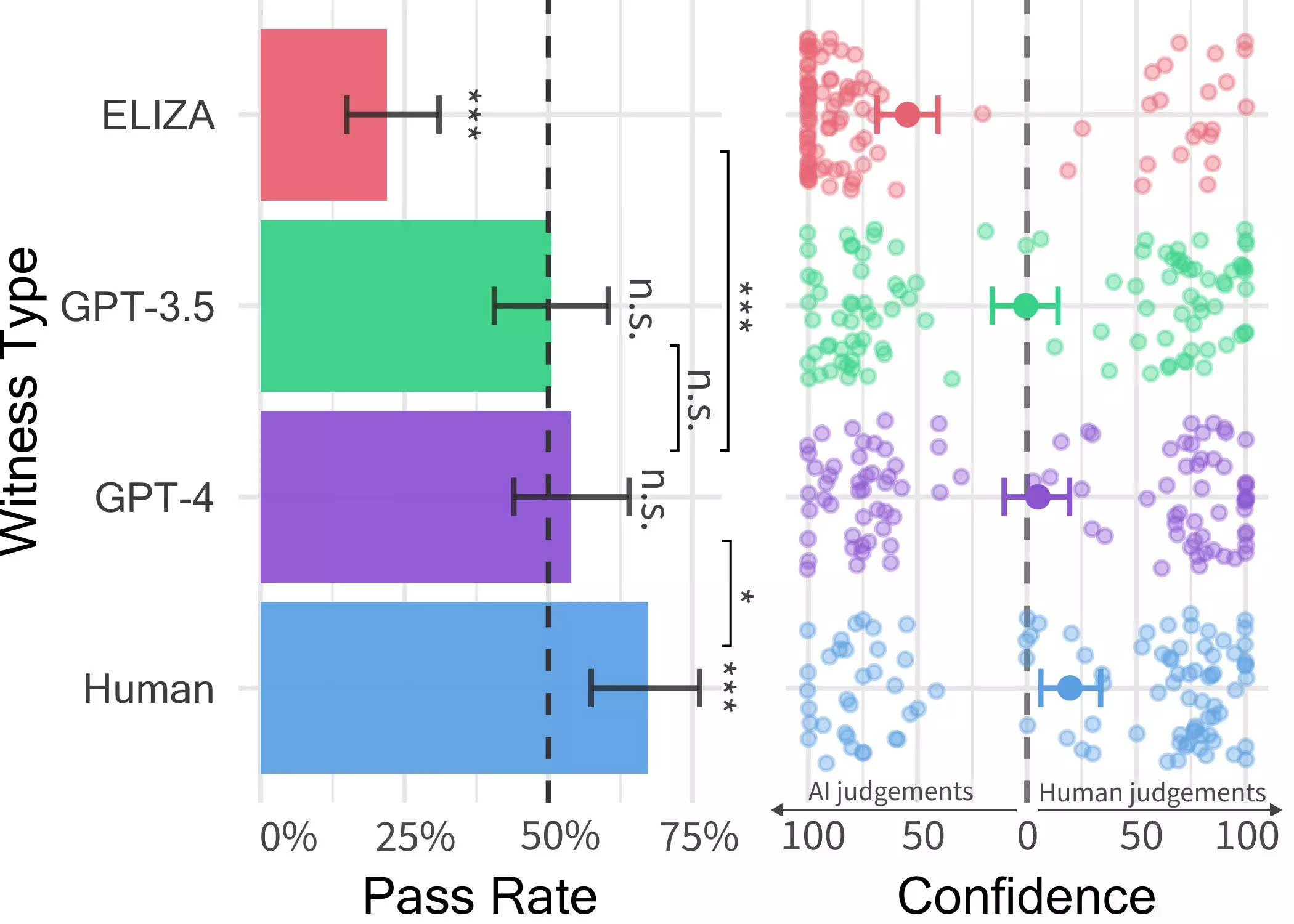
In this novel experiment, participants engaged in a two-player game where they were randomly matched with either another human or an AI model and had five minutes to converse freely with them. Jones and his team introduced three different LLMs – GPT-4, GPT 3.5, and ELIZA – as witnesses in the game. Interestingly, the users could often discern that ELIZA and GPT-3.5 were artificial entities, but determining whether GPT-4 was human or machine posed a significant challenge. Participants’ ability to distinguish between human and AI while conversing with GPT-4 was no more accurate than random guessing.
Despite real humans outperforming AI models in persuading interrogators about their humanity, the results indicate that people may struggle to ascertain whether they are conversing with a human or an AI system. This blurred line between humans and machines could have profound implications, particularly in scenarios like client-facing automation, fraud, or misinformation. As LLMs like GPT-4 continue to advance, the risk of deception in human-AI interactions heightens, potentially fostering distrust in online conversations.
Jones and Bergen’s Turing test outcomes shed light on the remarkable resemblance between LLMs, especially GPT-4, and humans in conversational settings. The researchers are now contemplating enhancing and relaunching their public Turing test to explore additional hypotheses. Delving deeper into how people differentiate between humans and LLMs, future studies like a three-person version of the game could offer valuable insights into the evolving dynamics of human-AI interactions. With the intersection of technology and human communication becoming increasingly intricate, understanding the nuances of these interactions is crucial for navigating the evolving digital landscape.
Leave a Reply