In the rapidly advancing field of artificial intelligence, large language models (LLMs) stand out as remarkable examples of machine learning capabilities. Developers have traditionally relied on two prominent techniques to tailor these models to specific tasks: fine-tuning and in-context learning (ICL). A recent groundbreaking study conducted by researchers from Google DeepMind and Stanford University sheds light on the comparative effectiveness of these methodologies in terms of their generalization abilities. While both approaches serve unique purposes, the findings suggest that ICL not only provides superior generalization performance but also comes with the trade-off of higher computational costs during inference. This intricate relationship underscores the necessity for organizations to understand these techniques’ nuances to optimize model efficacy within their operational contexts.
Understanding Fine-Tuning and In-Context Learning
Fine-tuning is akin to a masterclass in skill enhancement. By taking a pre-trained LLM and subjecting it to additional training on a smaller, specialized dataset, developers can recalibrate the model’s internal parameters. This process refines the model’s abilities, teaching it new knowledge or skills pertinent to the specific tasks at hand.
Conversely, in-context learning, as the name implies, relies on providing a contextual framework within the input prompt without altering the model’s underlying parameters. Instead of reshaping the model, ICL exploits examples of desired tasks embedded within prompts, empowering the LLM to adapt its outputs based on the immediate context. This distinction highlights the fundamental differences in approach and the implications for performance across varied use cases.
Experimental Design and Findings
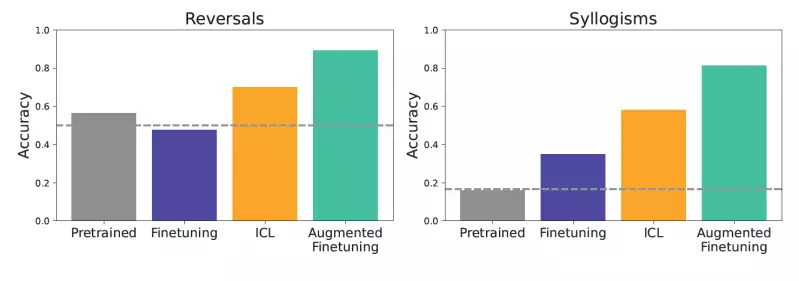
The researchers designed sophisticated experiments to rigorously assess how well these models generalize to new tasks under these two training paradigms. They created controlled synthetic datasets characterized by complex, self-consistent structures—such as fictional family trees or hierarchies of imaginary concepts. To isolate the models’ learning capabilities, the researchers used nonsense terms in place of recognizable nouns, adjectives, or verbs, ensuring no overlap with the data available during pre-training.
Testing focused on generalization challenges, including deductive reasoning tasks like reversals and syllogisms. Such tests evaluated whether models could logically navigate the syntactic and semantic nuances present in input data. While pre-trained models performed poorly, the findings illuminated that ICL-driven models often outperformed those relying solely on fine-tuning, exhibiting superior abilities in making logical deductions and inferring relationships.
Deciphering Trade-offs in Model Training
One compelling aspect discussed in the research is the trade-off inherent in using ICL versus fine-tuning. While ICL mitigates the need for upfront fine-tuning—a cost-effective choice—it requires substantial computational resources during each interaction with the model. This complexity prompts essential questions: When does the enhanced generalization justify the computational expense? How can organizations leverage this knowledge effectively?
The crux of the researchers’ proposal lies in their exploration of augmenting fine-tuning with insights gained from ICL. By using the LLM’s contextual reasoning to generate diverse training examples, they forged a path to improve generalization without succumbing entirely to either model’s limitations. Through a multi-faceted approach that included both local and global strategies for data augmentation, the benefits of combining ICL and fine-tuning became apparent, resulting in significant performance enhancements.
Real-World Implications of Augmented Fine-Tuning
For enterprises, the implications of these findings are profound. The integration of ICL methodologies into the fine-tuning process can lead to the development of LLM applications that respond adeptly to diverse inputs. By investing in the creation of ICL-augmented datasets, organizations are not merely refining their models; they are paving the way for creating robust and reliable LLM applications capable of greater generalization across varying contexts.
The study underscores a pivotal shift in perspective regarding model training, advocating for a nuanced approach that embraces the complexities of ICL within fine-tuning. As developers continue to refine these applications, they must carefully weigh the cost-benefit dynamics associated with augmented fine-tuning against traditional methods, ensuring that the pursuit of enhanced performance aligns with operational demands.
A Future of Continuous Improvement
Looking ahead, the nuances of adapting LLMs for bespoke applications will become increasingly important. The interplay between fine-tuning and in-context learning will shape the training landscape, prompting further innovation in model construction. Despite the inherent complexity of ICL and the challenges posed by computational demands, the potential for enhanced generalization presents an exciting frontier for machine learning.
As research expands into the dynamics of learning and generalization in foundation models, the journey will undoubtedly influence the design of future LLMs. Developers keen on harnessing the power of augmented fine-tuning should remain attuned to the evolving research landscape, ensuring their models not only respond to immediate tasks but are also poised for unforeseen challenges in the ever-evolving world of AI.
Leave a Reply